临床诊断需要能够处理多模态医学输入(图像、病史、实验室结果)并生成多样化输出(文本报告和视觉内容如标注、分割掩码和图像)的模型。然而,现有医学AI系统割裂了这一统一过程:医学图像理解模型能解释图像但无法生成视觉输出,而医学图像生成模型能合成图像但无法提供文本解释。这导致了数据表示、特征集成和任务级多模态能力的缺失。
为此,我们提出了一个多层次框架,通过观察-知识-分析(OKA)范式模拟临床诊断流程。具体来说:在观察层面,我们构建了包含超过560万样本的UniMed-5M数据集,将多样化的单模态数据重新格式化为多模态配对数据;在知识层面,我们提出了渐进式课程学习,系统性地引入医学多模态知识;在分析层面,我们推出了UniMedVL——基于OKA范式设计的医学统一多模态模型,在单一架构内全面实现图像理解与生成任务的综合分析。
UniMedVL在5个医学图像理解基准上取得卓越性能,同时在8种医学成像模态的生成质量上媲美专用模型。更重要的是,我们的统一架构实现了双向知识共享——生成任务增强了视觉理解特征,证明了在单一医学框架内整合传统上分离的能力能够解锁跨多样化临床场景的改进。
考虑一位放射科医生检查疑似肺部病变的场景:他们系统性地处理胸部X光片(视觉)、既往CT扫描(跨模态比较)和患者病史(文本),以生成多种互补的输出:
这体现了临床诊断需要统一处理多模态输入以生成多样化的多模态输出,单独的文本报告(缺乏空间定位)或单独的视觉标注(缺乏推理上下文)都不足够。
尽管多模态融合已被证明能显著改善临床决策,但当前医学AI在三个关键层面仍然存在碎片化:
① 数据层面:医学数据集仍然以单模态为主,尽管有明确证据表明多模态整合能显著提高诊断准确性。大多数数据集缺乏统一训练所需的成对多模态结构。
② 特征层面:当前方法缺乏系统化的渐进式训练策略来学习深层跨模态关系。大多数方法只是简单拼接特征,而不是从基础模式识别逐步构建到复杂的多模态推理。
③ 任务层面:虽然通用领域模型在统一架构方面取得了进展,但医学领域仍然缺乏真正统一的模型。例如,HealthGPT虽然展示了理解和生成能力,但需要重新加载不同的模型checkpoint才能切换任务类型——这一限制阻碍了临床工作流中的无缝多任务操作。
📊 性能差距:当前医学AI系统在诊断挑战中的准确率不到60%,而人类专家的准确率超过90%,这突显了统一方法的迫切需求。
UniMedVL通过OKA框架在单一模型checkpoint内全面实现医学多模态的理解与生成能力。一旦加载模型,即可无缝处理:
关键优势:无需离线切换checkpoint,单一模型即可完成所有任务 ✨
5.6M+
训练样本
9种医学成像模态
96.29
平均gFID
媲美专用生成模型
UniMedVL遵循临床工作流引导的三层次框架,模拟医生处理医学信息的过程:
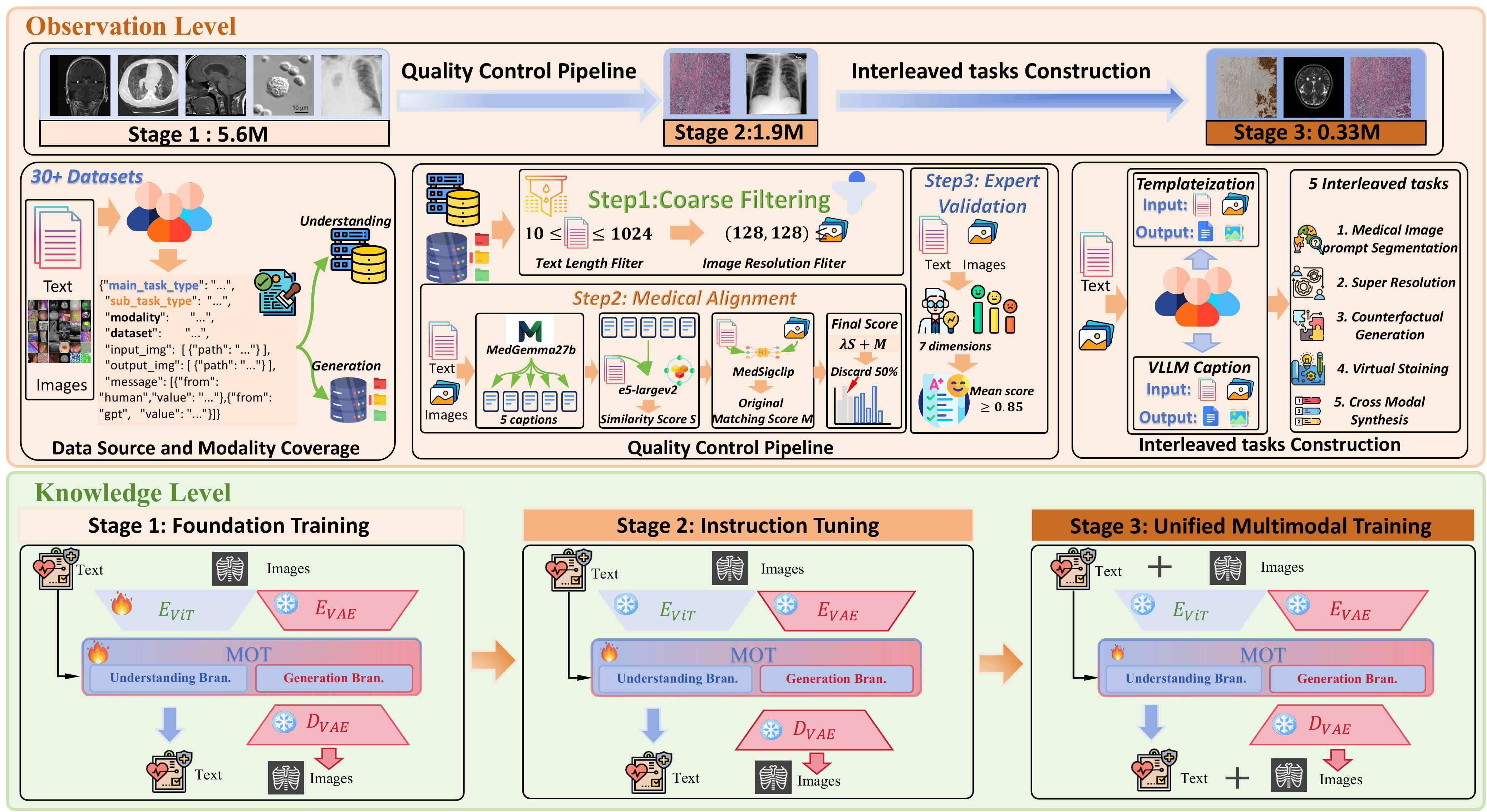
完整的数据处理流程和模型架构概览
三阶段渐进式课程学习:
单一模型,全面覆盖理解、生成与交织任务
PathVQA
53.5%
vs. HealthGPT-L14 44.4%
OmniMedVQA
85.8%
vs. GMAI-VL 88.5%
VQA-RAD
61.9%
vs. GMAI-VL 66.3%
GMAI-MMBench
60.75%
综合医学多模态评测
胸部X光 (CXR)
73.04
gFID
病理切片 (HIS)
149.01
gFID
眼底照片 (CFP)
53.20
gFID
CT扫描
73.04
gFID
MRI磁共振
90.36
gFID
OCT光学相干
99.27
gFID
超声影像
95.38
gFID
内窥镜
133.11
gFID
平均gFID: 96.29 BioMedCLIP: 0.706
虚拟免疫组化染色
20.27 / 0.456
PSNR / SSIM
MRI超分辨率 (4×)
27.29 / 0.890
PSNR / SSIM
跨模态合成 (T2↔FLAIR)
25.07 / 0.882
平均 PSNR / SSIM
反事实生成(图像+文本解释)
gFID: 27.17 | AUROC: 0.797
BLEU-3: 0.2641 | METEOR: 0.4486 | ROUGE-L: 0.4649
无缝任务切换
无需切换checkpoint
即可完成所有任务
双向知识共享
生成任务增强理解
理解任务优化生成
临床工作流整合
符合医生实际诊断
观察-知识-分析流程
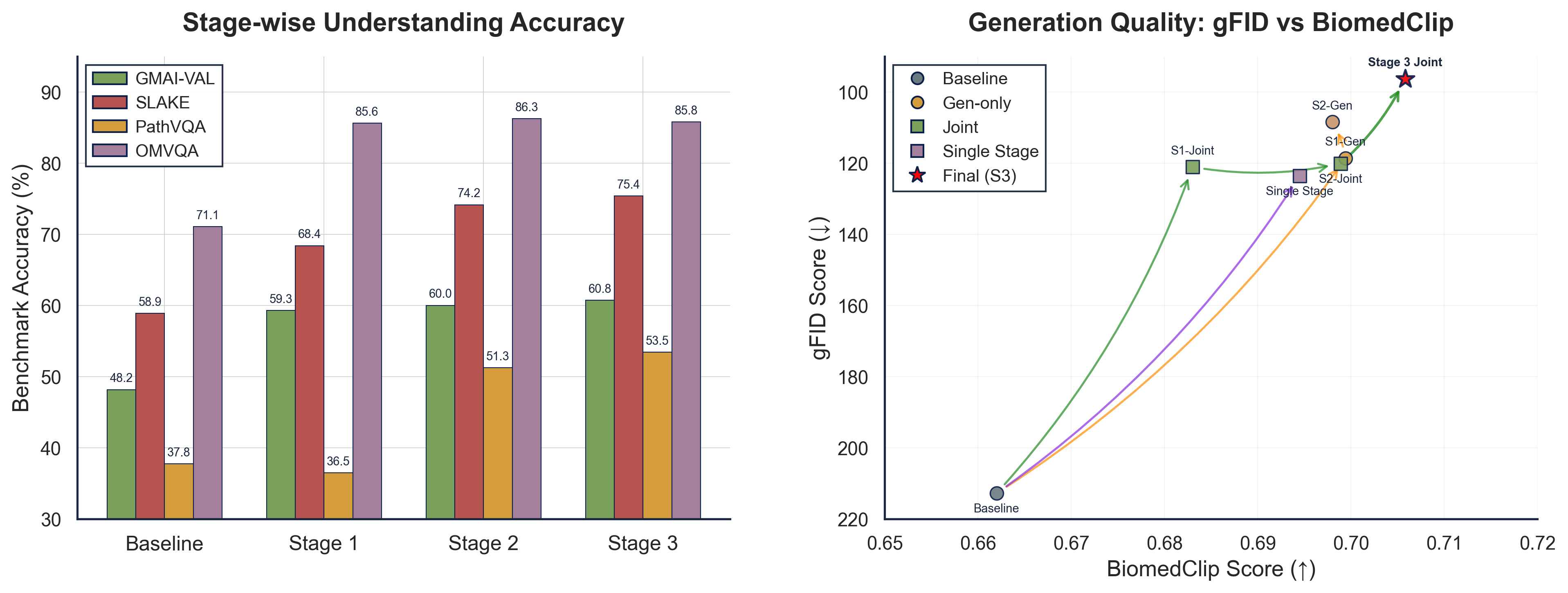
不同训练阶段和模态下的全面性能对比
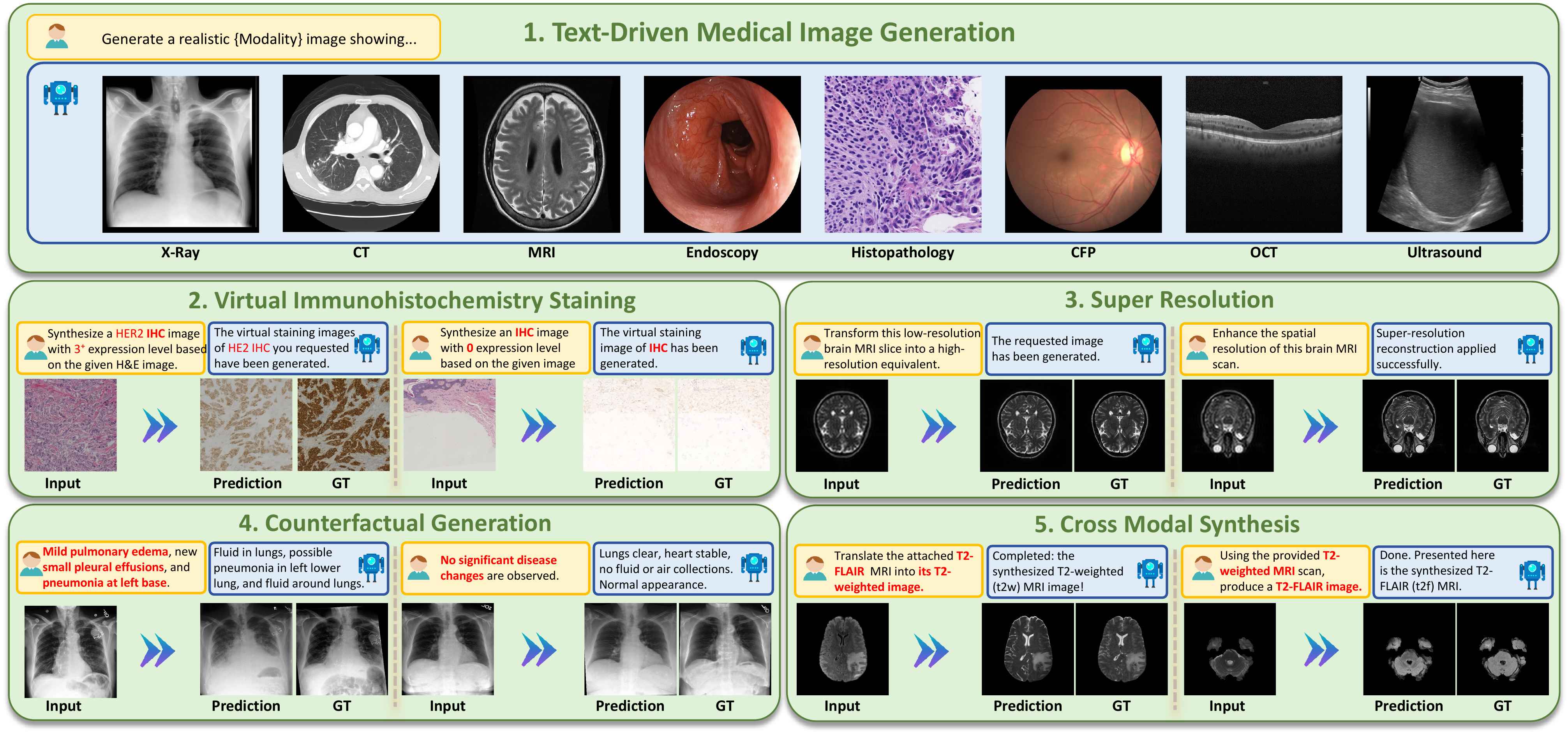
UniMedVL多模态能力的全面可视化展示

准确率: SLAKE 75.4% | PathVQA 53.5%
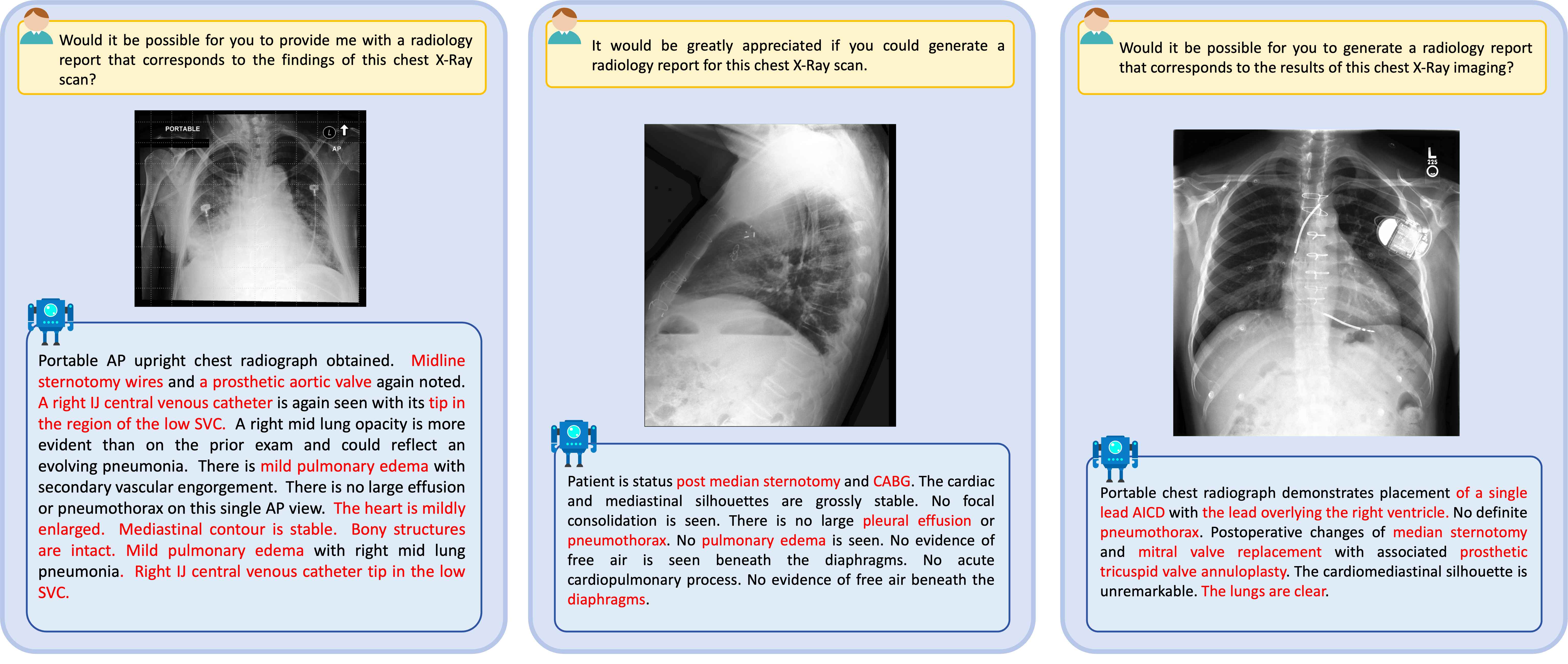
生成详细的医学诊断报告
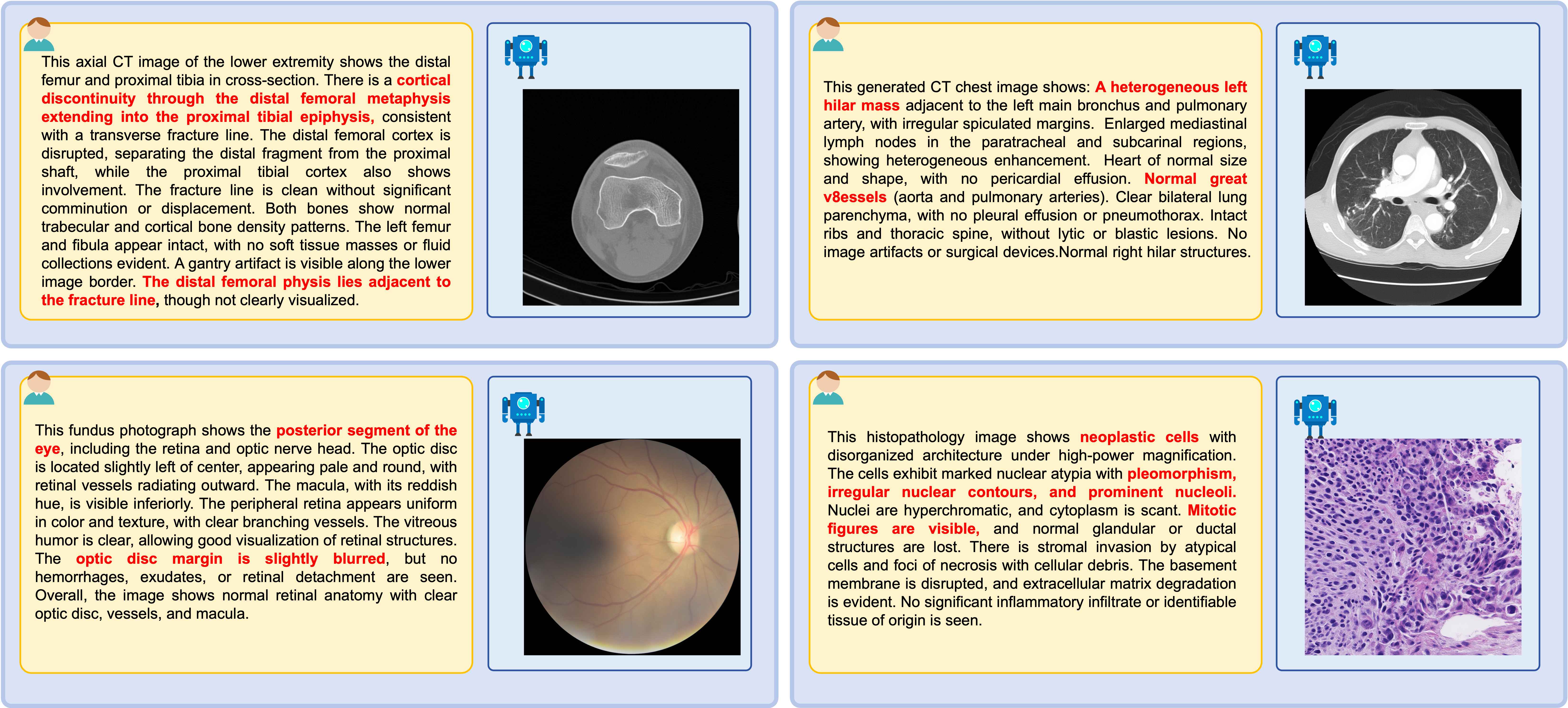
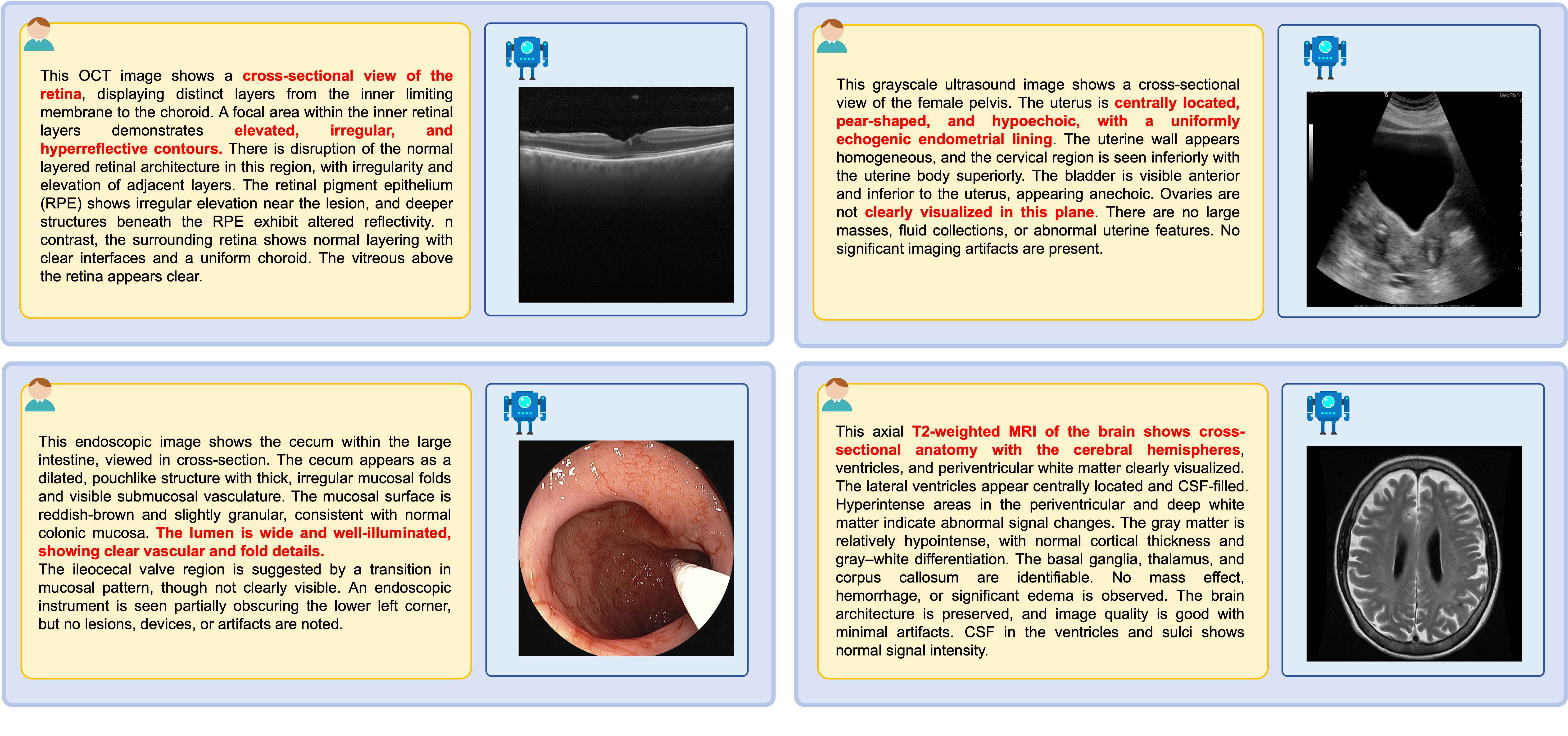
跨8种医学成像模态的高质量文本驱动图像生成
平均gFID: 96.29 | BioMedCLIP: 0.706
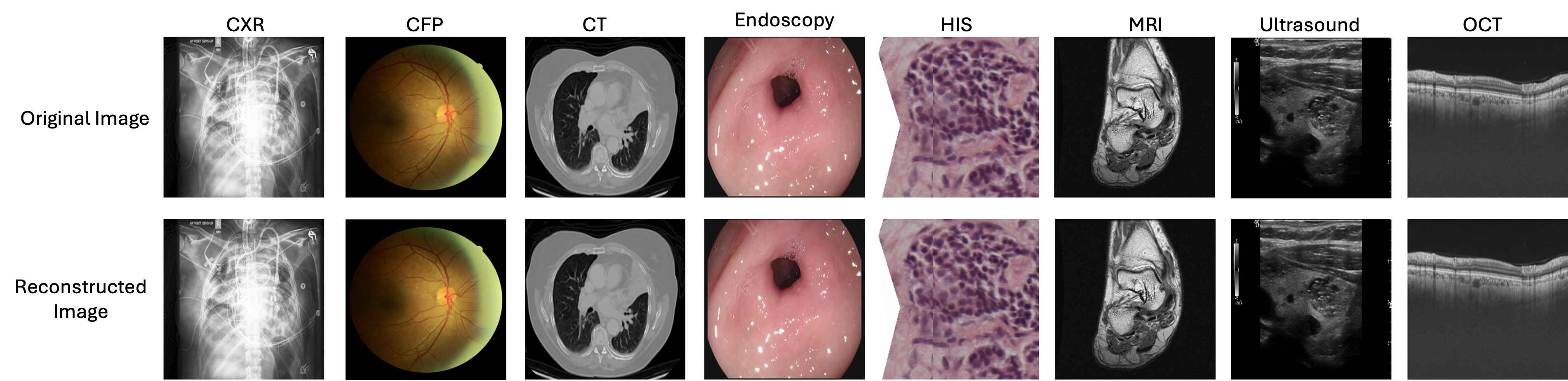
跨多种医学成像模态的定性对比
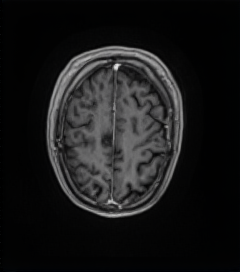
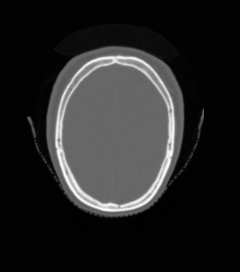
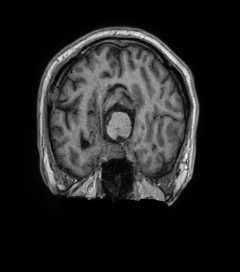
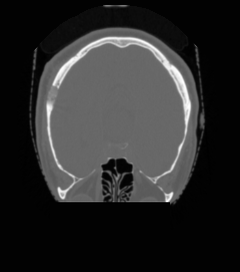

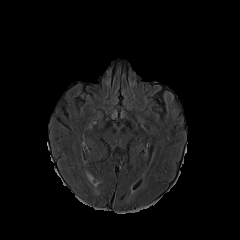
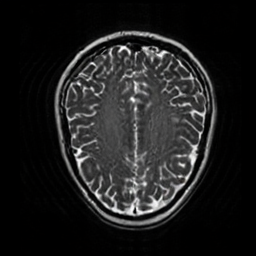
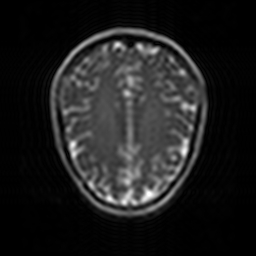

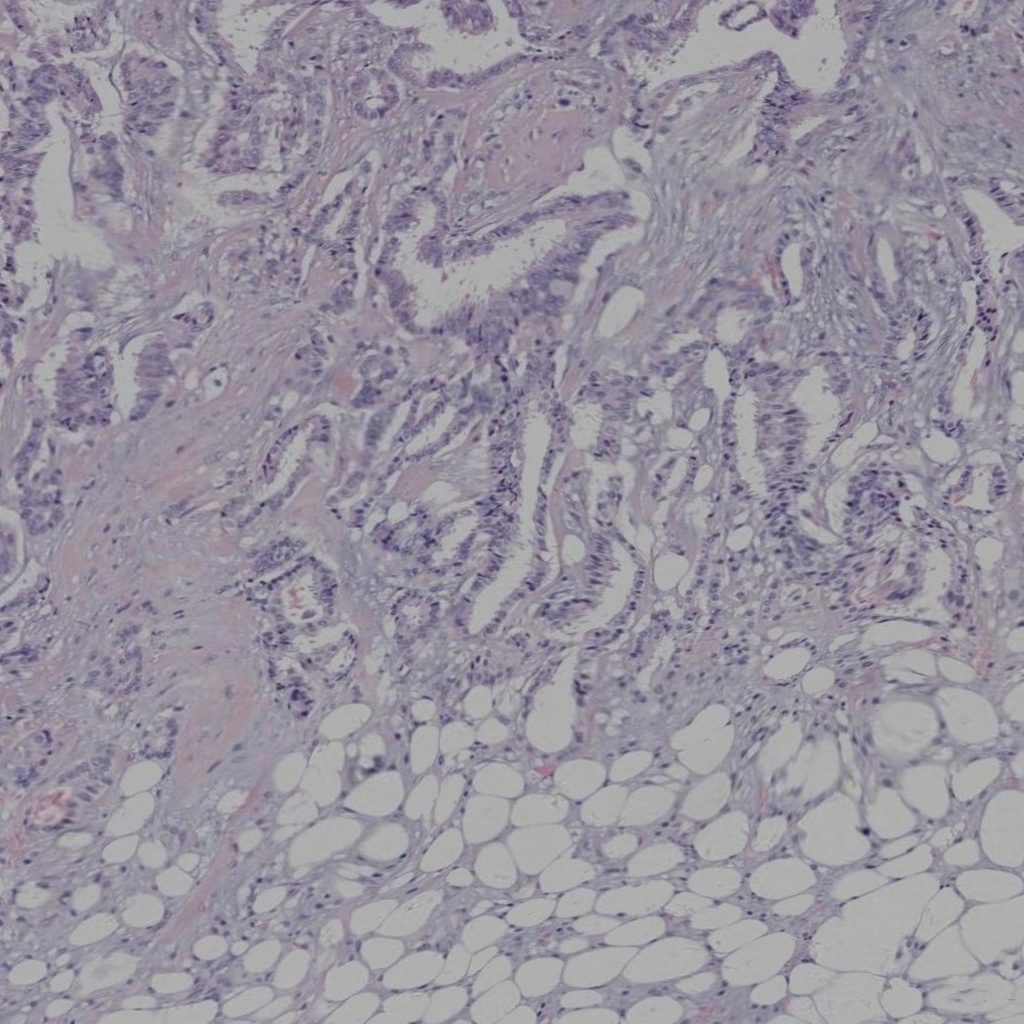

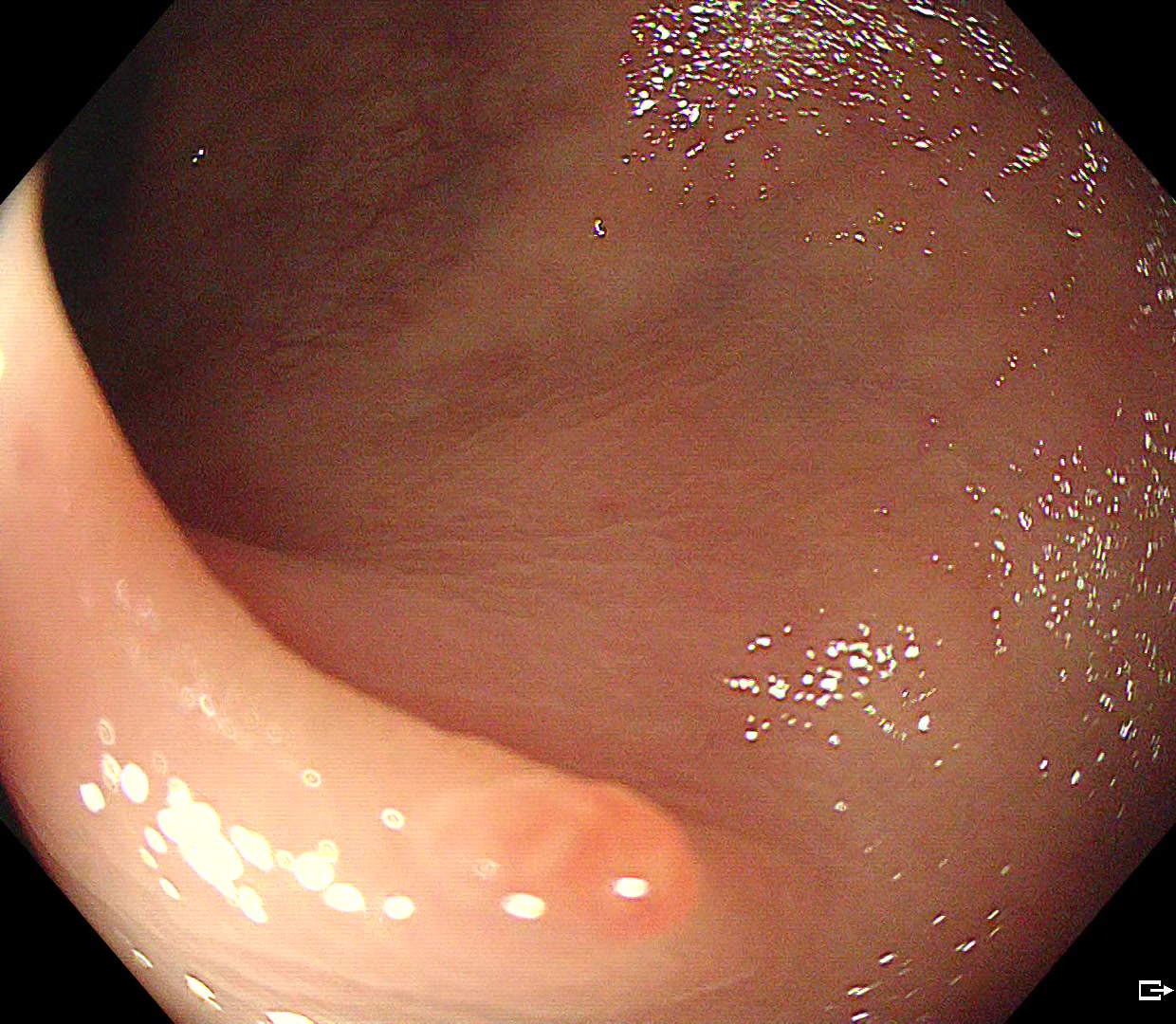
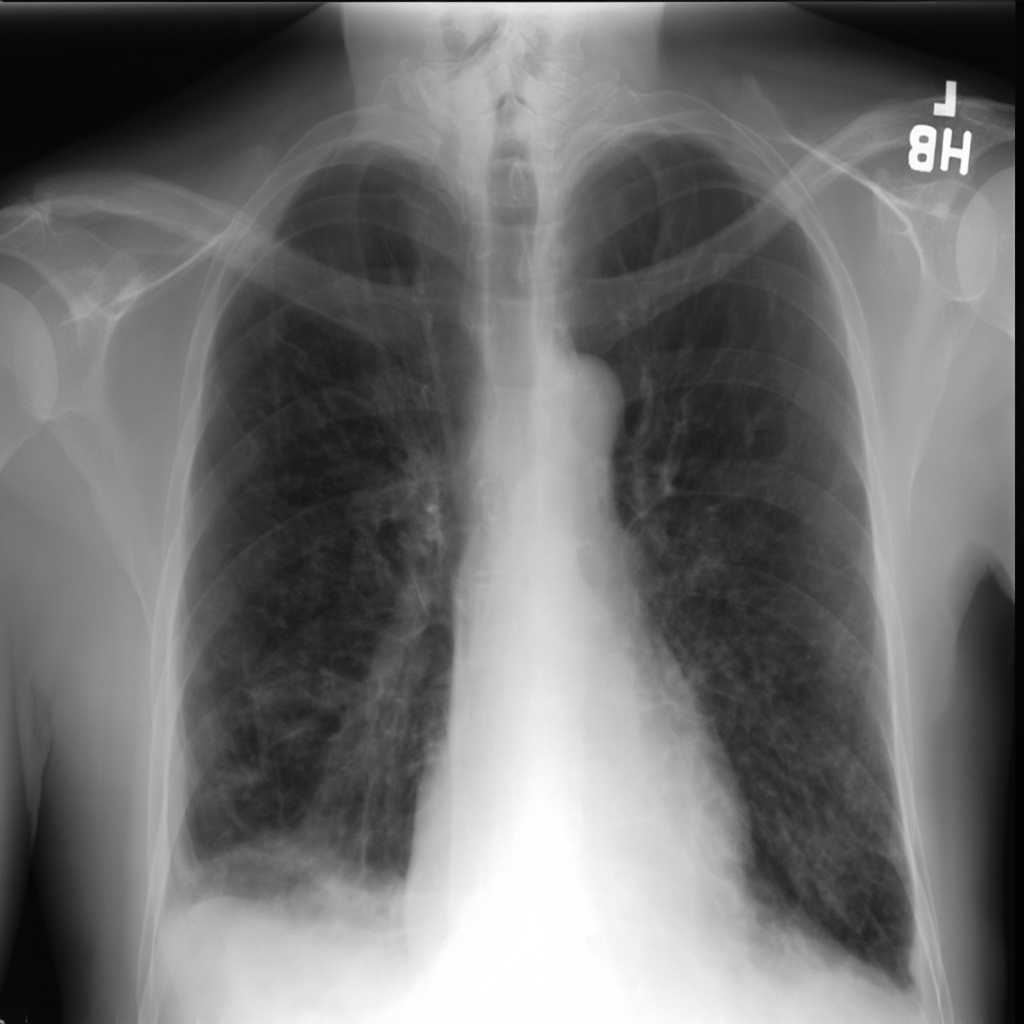
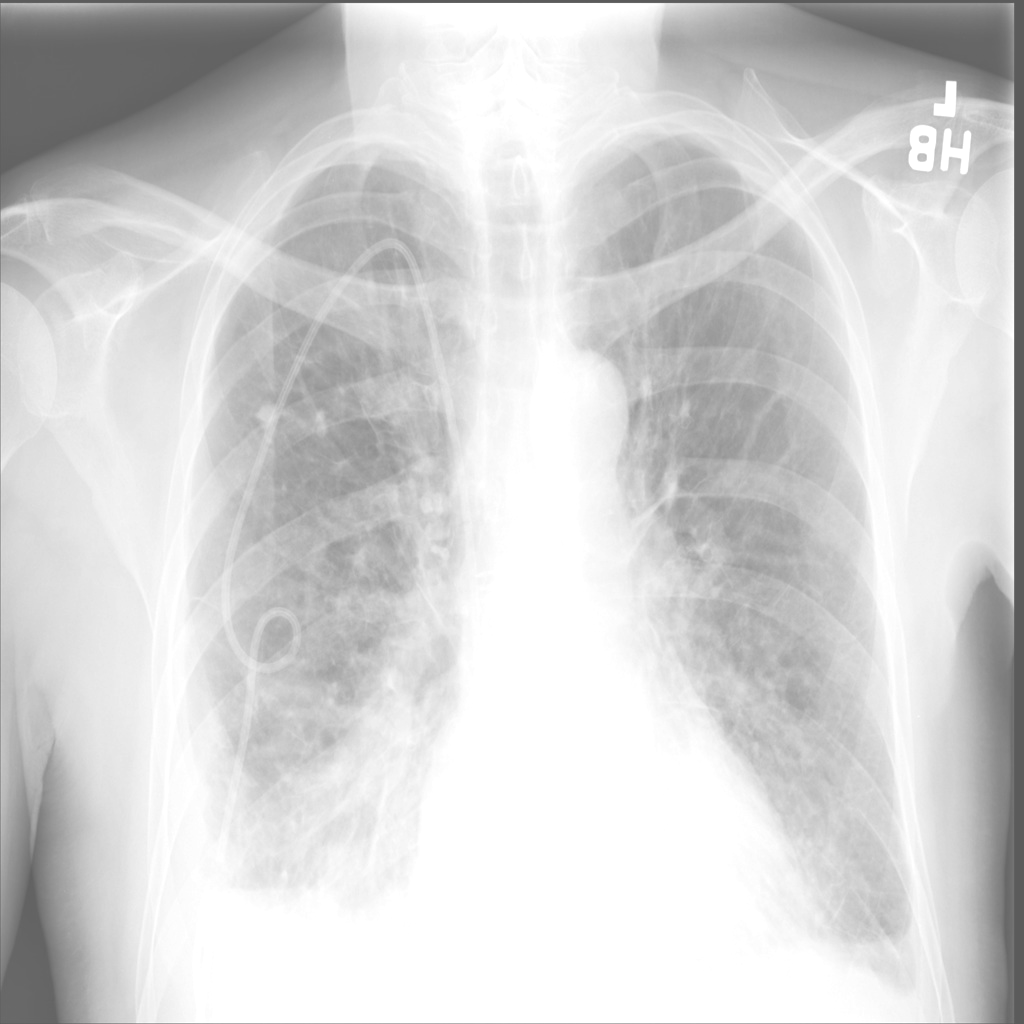

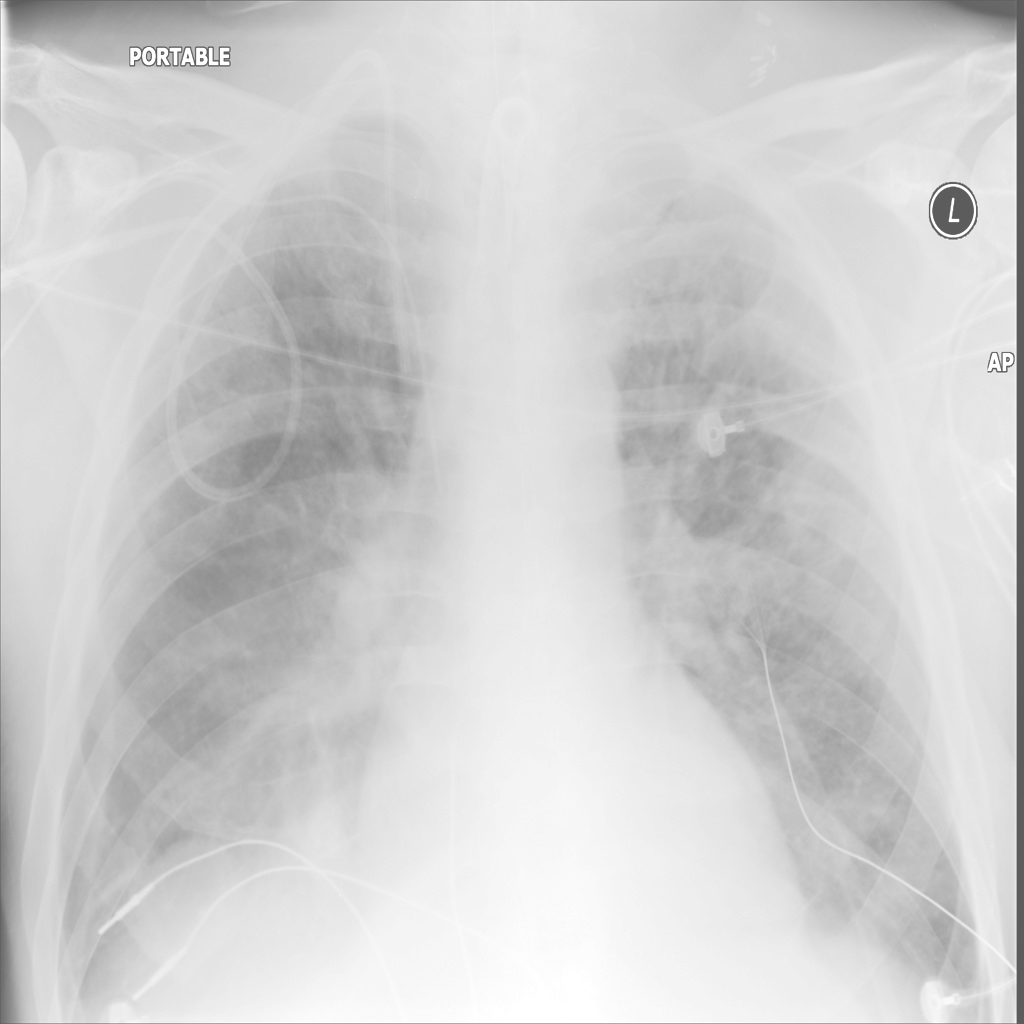
UniMedVL支持的八种不同医学成像模态
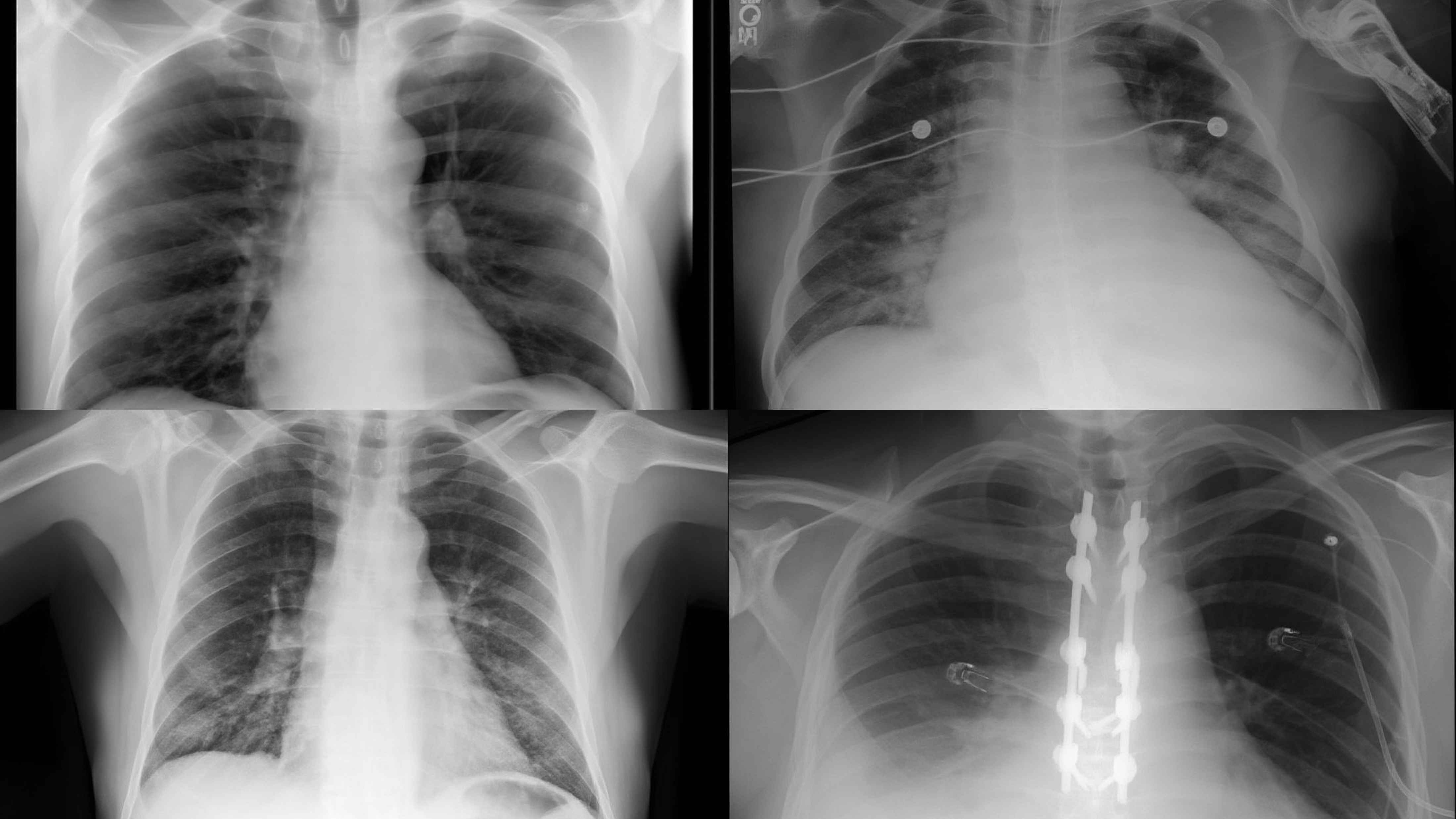
胸部X光 (CXR)
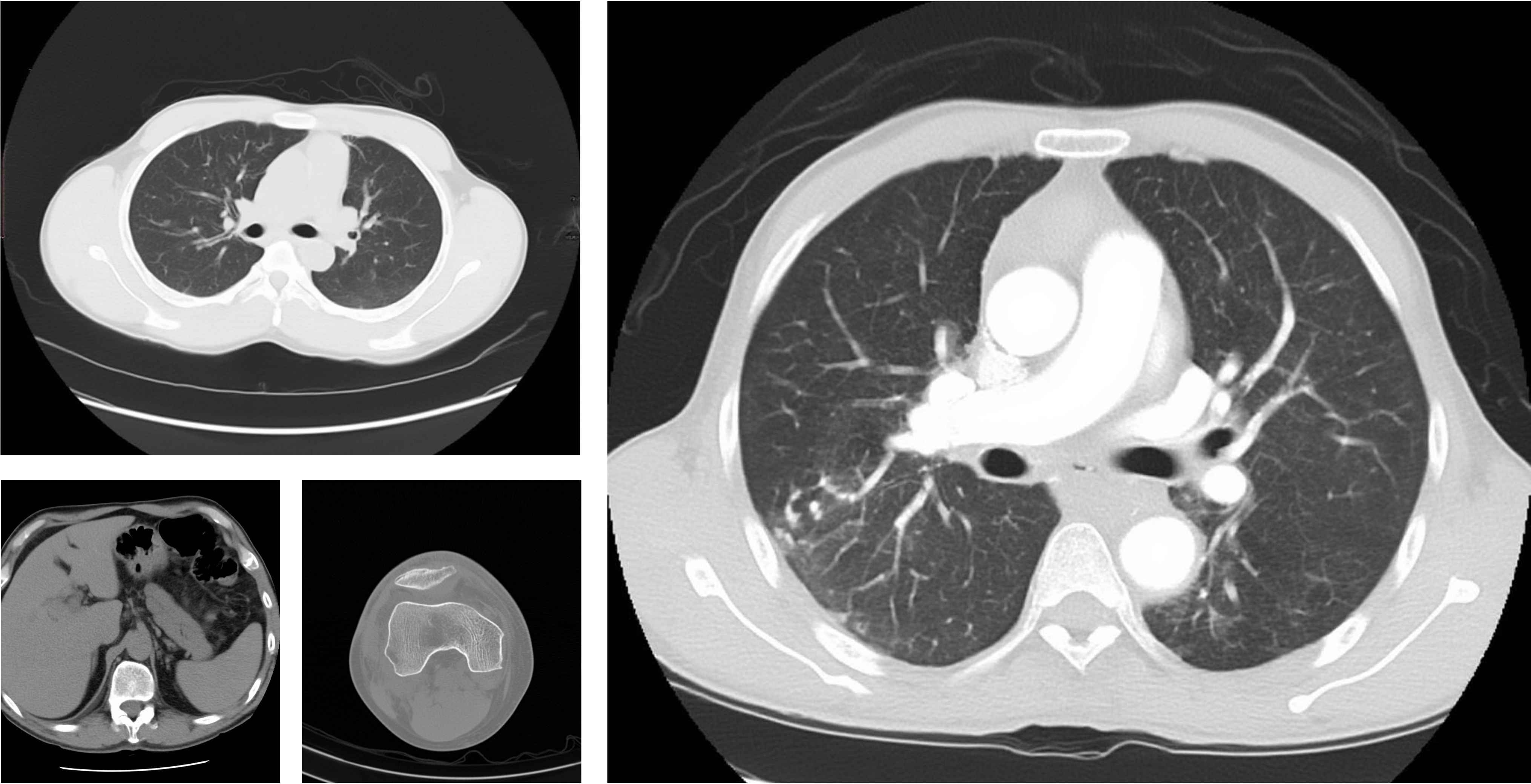
CT扫描
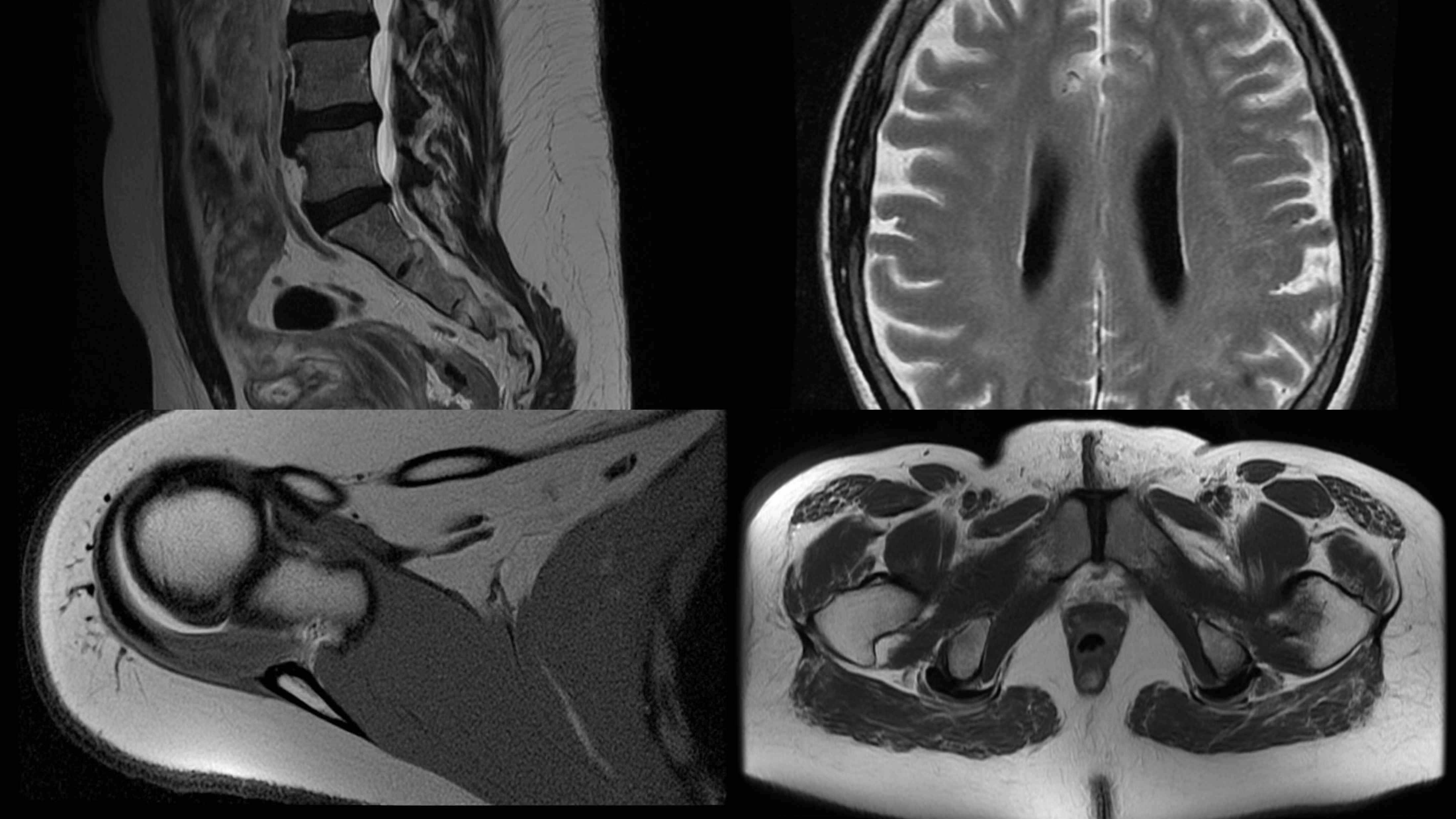
MRI磁共振
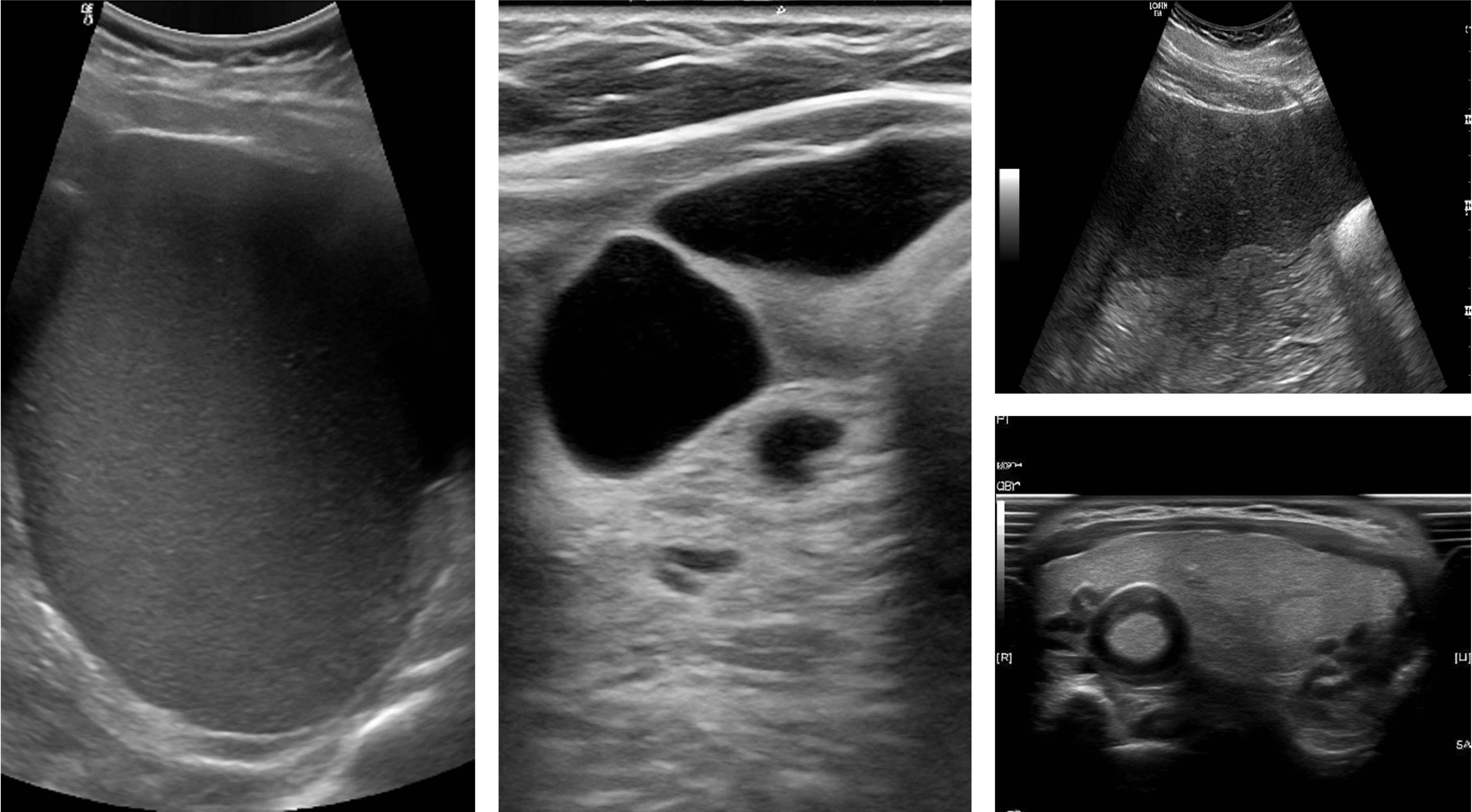
超声影像
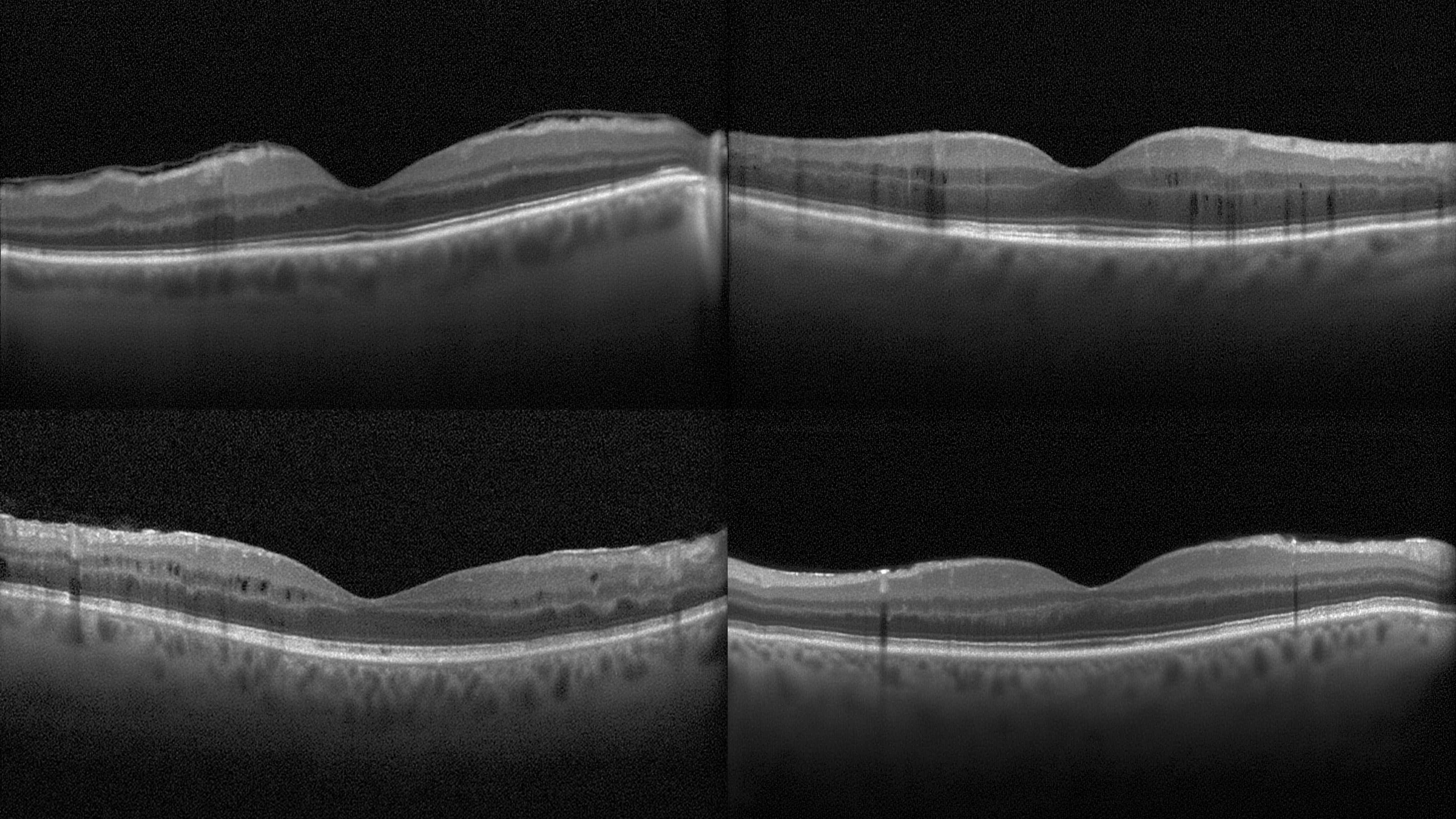
OCT光学相干断层扫描
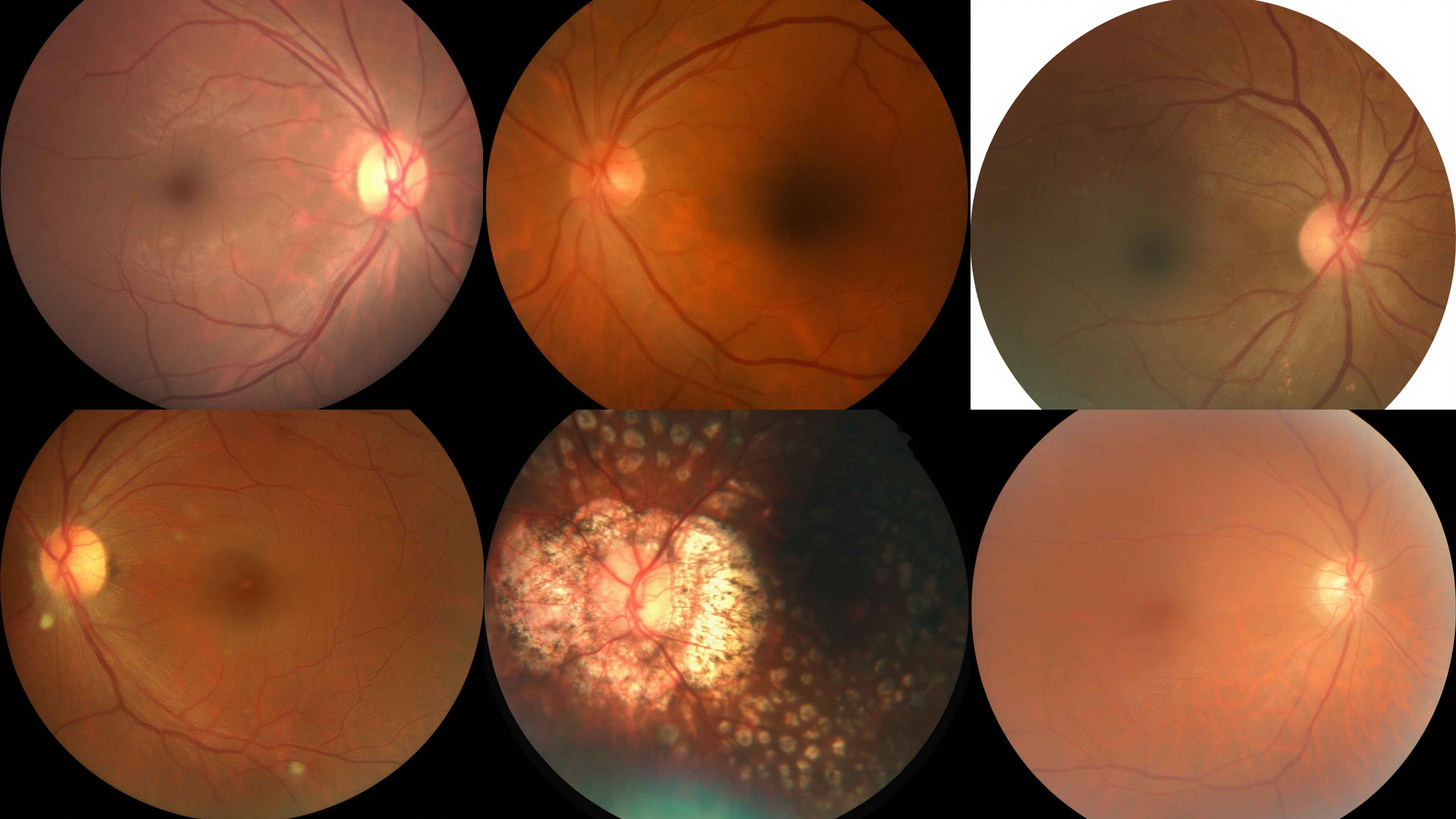
眼底照片
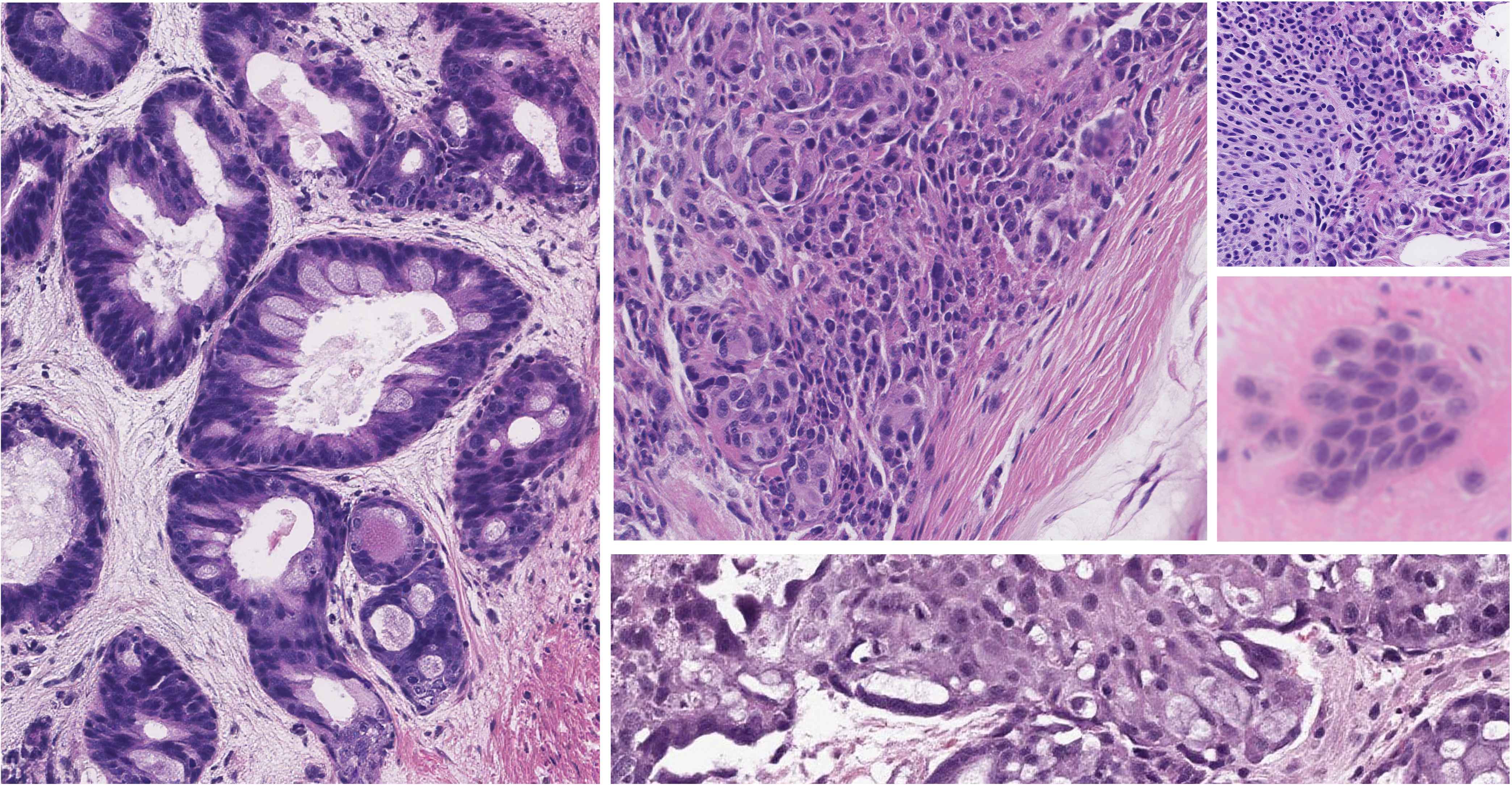
病理切片 (HIS)
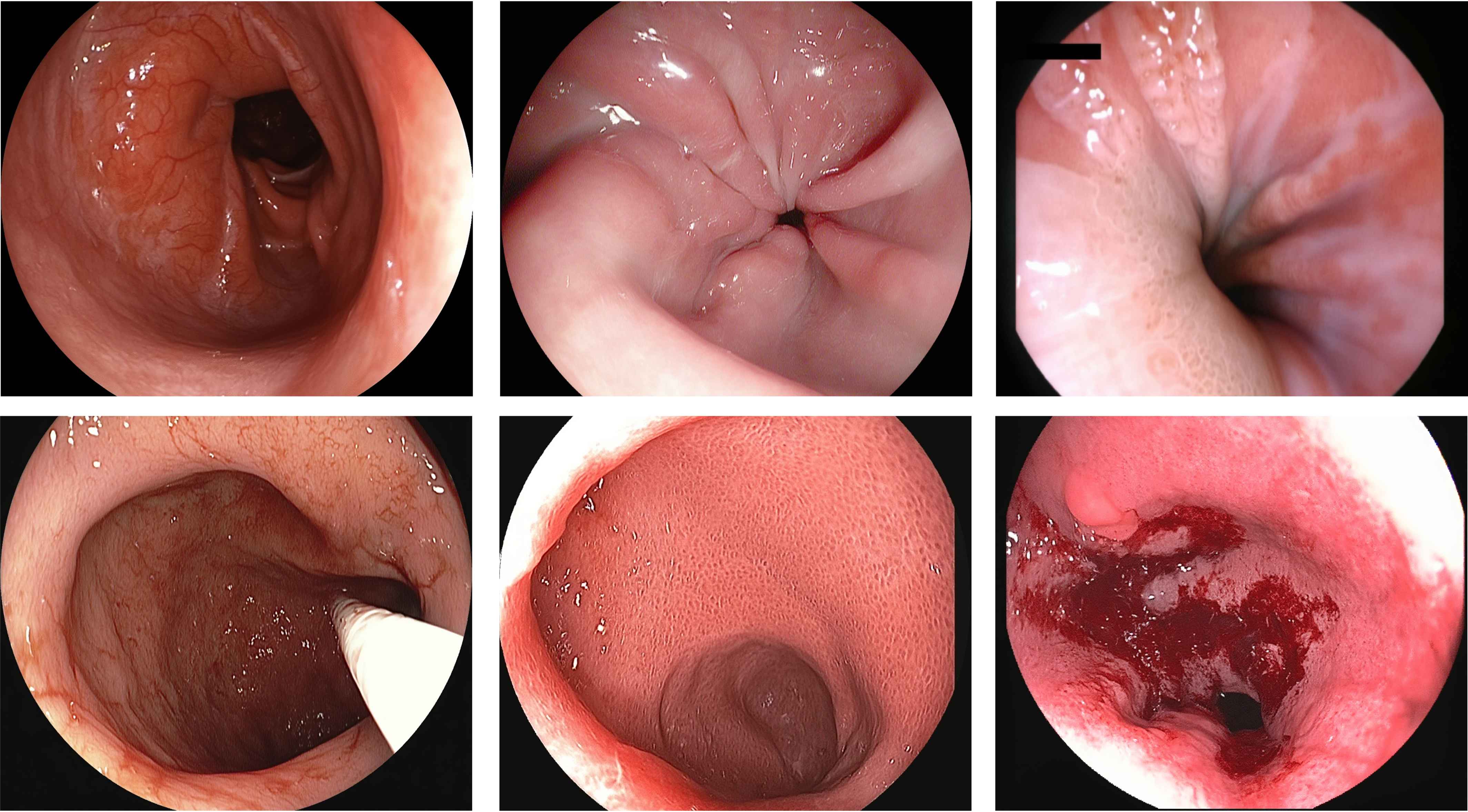
内窥镜