OphCLIP
Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Vision-language pretraining (VLP) has enabled open-world generalisation beyond predefined labels — a critical capability in surgery, where the diversity of procedures, instruments, and patient anatomies makes fixed label sets impractical. However, applying VLP to ophthalmic surgery presents unique challenges: limited vision-language data, intricate procedural workflows spanning hours, and the need for hierarchical understanding from fine-grained surgical actions to global clinical reasoning.
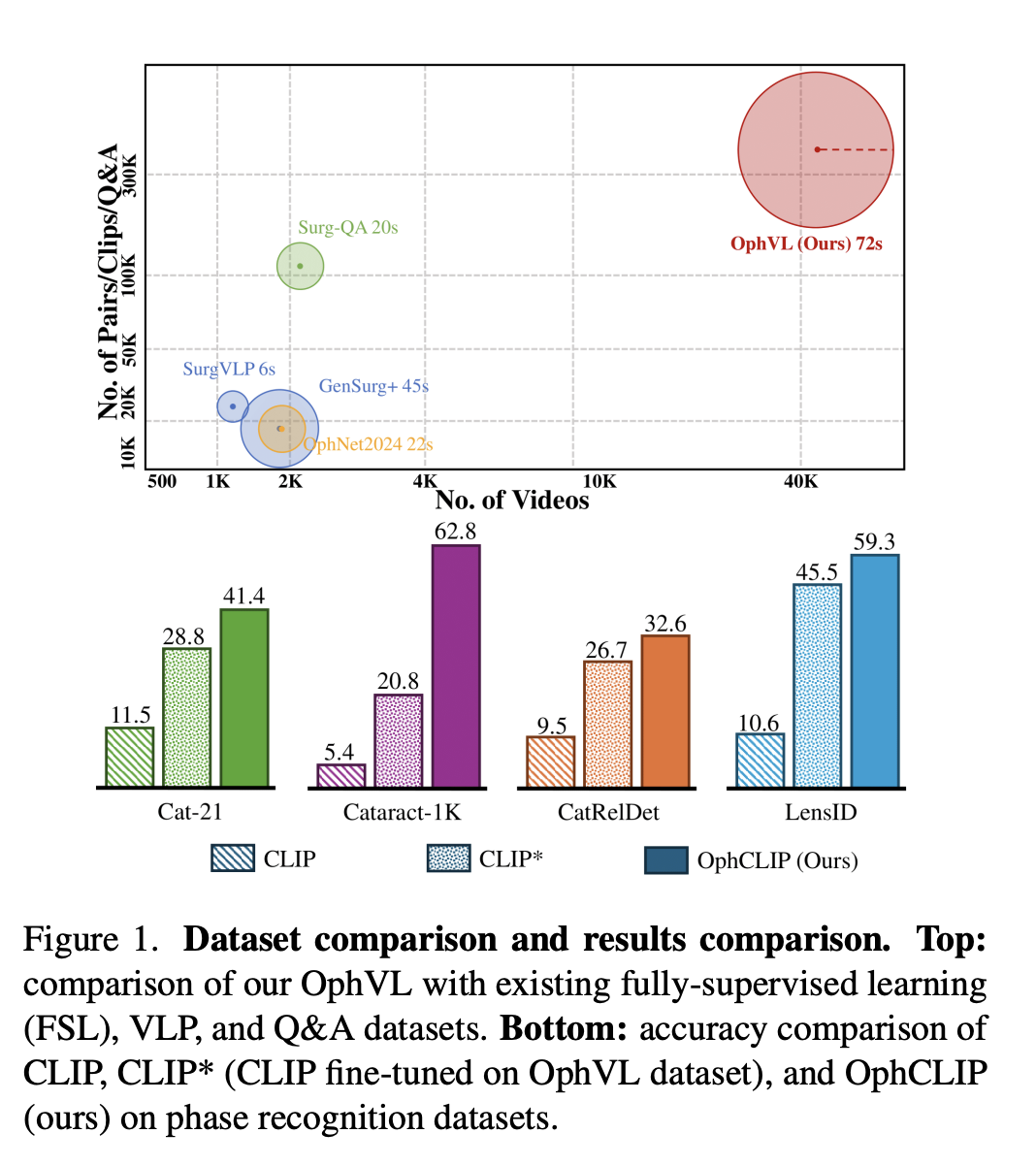
To address these challenges, we introduce OphVL — the first large-scale, hierarchically structured VLP dataset for ophthalmic surgery, containing over 375K video-text pairs from 7.5K hours of surgical video. This makes OphVL 15× larger than existing surgical VLP datasets. It captures a diverse range of attributes: surgical phases, operations, instruments, medications, disease causes, surgical objectives, and postoperative care.
Building on OphVL, we propose OphCLIP, a hierarchical retrieval-augmented VLP framework. OphCLIP learns short-term representations by aligning video clips with detailed narrations, and long-term representations by matching full videos with structured title summaries. It further leverages a knowledge base of silent surgical videos through retrieval-based supervision. Evaluations across 11 benchmark datasets for phase recognition and multi-instrument identification demonstrate OphCLIP's robust zero-shot generalisation, establishing it as a foundation model for ophthalmic surgery.
🌟 Core Highlights
01 — OphVL: The Largest Ophthalmic Surgical VLP Dataset
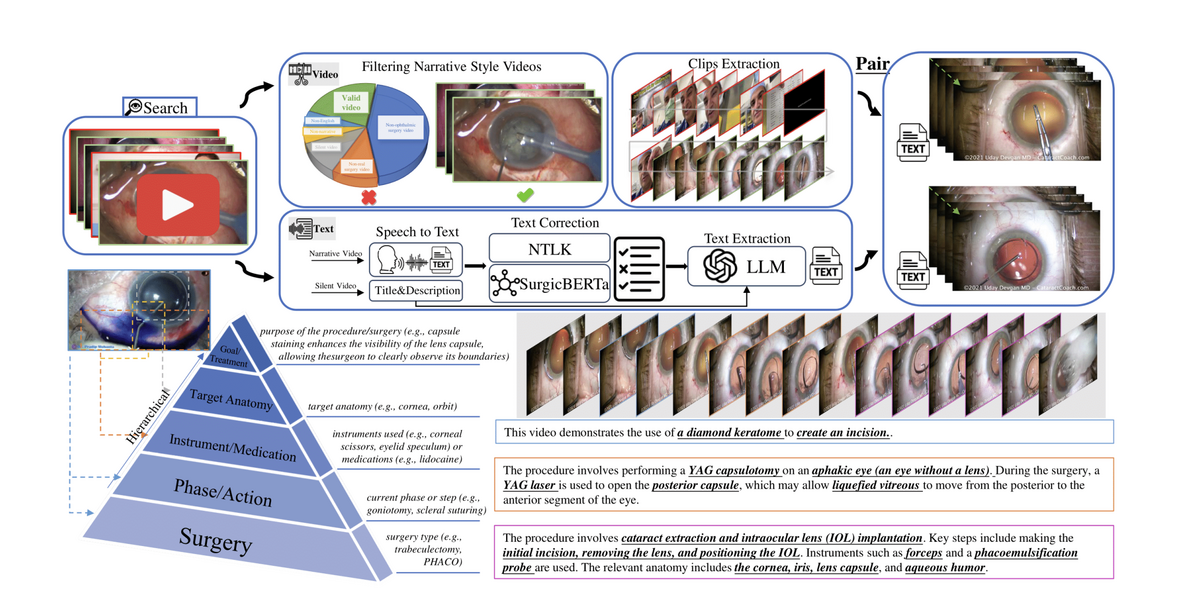
OphVL contains 375K clip-text pairs extracted from 13,654 narrated videos and 30,636 silent videos (totalling 9,363 hours). In collaboration with three practising ophthalmologists, over 3,000 ophthalmic surgery terms were compiled to guide YouTube channel discovery and video collection. A rigorous curation pipeline — filtering for narrative style, ASR-based transcription with Whisper Large-V3, denoising via SurgicBERTa, and LLM-guided text rewriting — produces high-quality hierarchical video-text pairs.
OphVL captures tens of thousands of attribute combinations spanning surgeries, phases, instruments, medications, eye disease causes, surgical objectives, and postoperative care — making it the most comprehensive ophthalmic surgical dataset to date.
02 — Hierarchical Retrieval-Augmented Pretraining
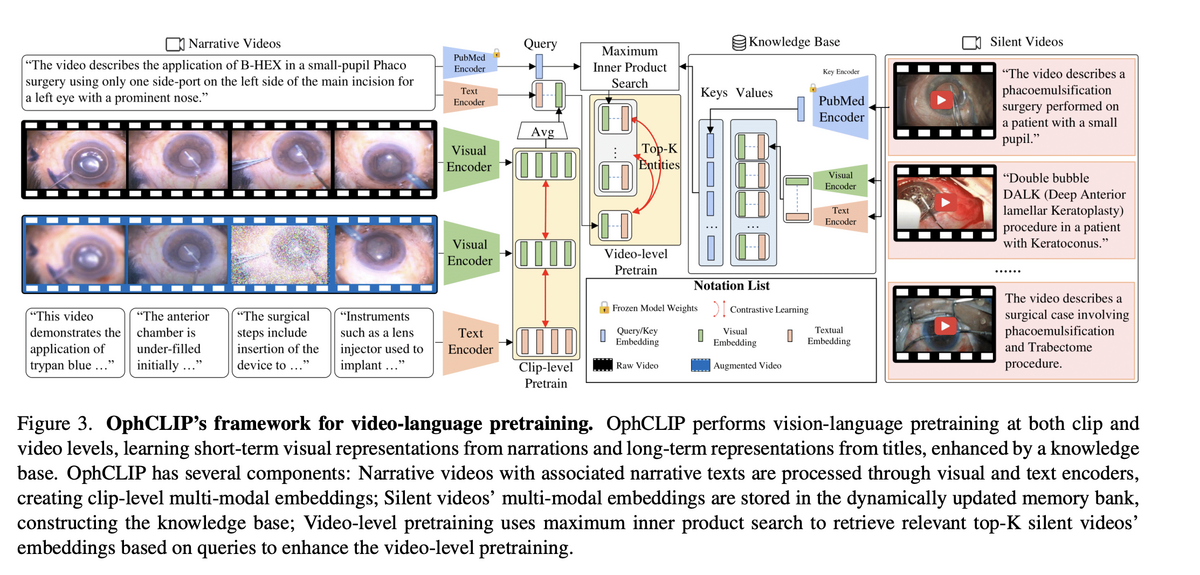
OphCLIP performs vision-language pretraining at two hierarchical levels. At the clip level, short video segments are aligned with detailed narration texts via contrastive learning, capturing fine-grained surgical actions and instrument usage. At the video level, entire procedure videos are matched with high-level title summaries, building long-term procedural context and clinical reasoning.
The key innovation is silent-video retrieval augmentation: a dynamically updated memory bank stores multi-modal embeddings of 30K+ silent surgical videos. Using maximum inner product search (MIPS), the system retrieves the top-K most relevant silent videos for each narrative video, adding them as auxiliary supervisory signals. This facilitates knowledge transfer across narrated and silent procedure videos — mirroring how surgeons learn from both explained and unexplained surgical footage.
03 — State-of-the-Art Zero-Shot Surgical Understanding
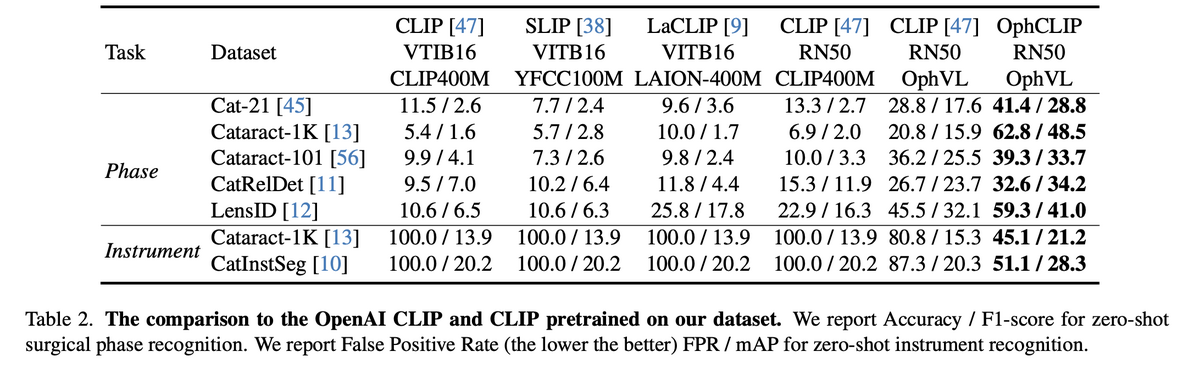
OphCLIP achieves strong zero-shot performance across 11 benchmark datasets covering phase recognition and multi-instrument identification. On Cataract-1K, OphCLIP reaches 62.8% accuracy / 48.5% F1 — vs. vanilla CLIP's 6.9%/2.0%. On Cat-21, it achieves 41.4% / 28.8% — nearly tripling CLIP's performance. These gains hold across both fine-grained (operation-level) and coarse-grained (phase-level) tasks.
For multi-instrument recognition, OphCLIP dramatically reduces false positive rates from 100% (CLIP) to 45–51%, while improving mAP. In few-shot linear probing with 100% training data, OphCLIP reaches 72.1% accuracy on Cat-21 — demonstrating strong transferable visual representations.
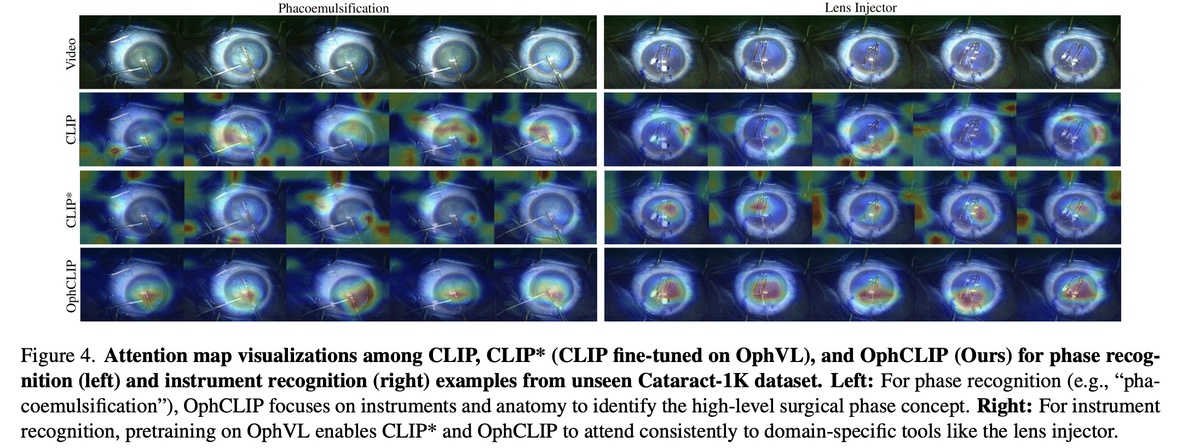
04 — Clinically Meaningful Attention Patterns
Attention map visualisations reveal that OphCLIP learns clinically meaningful focus patterns. For phase recognition (e.g., phacoemulsification), OphCLIP focuses on the relevant instruments and anatomical structures, while vanilla CLIP attends to irrelevant background regions. For instrument recognition, pretraining on OphVL enables both CLIP* and OphCLIP to consistently attend to domain-specific tools like the lens injector.
This cross-modal understanding — where the model prioritises clinically relevant regions in visual data that correspond to surgical concepts in text — demonstrates that OphCLIP has genuinely internalised ophthalmic surgical knowledge rather than relying on spurious visual correlations.
OphCLIP establishes a new paradigm for ophthalmic surgical AI by combining the largest surgical VLP dataset (OphVL, 375K pairs) with a hierarchical retrieval-augmented framework that learns from both narrated and silent surgical videos. Its robust zero-shot performance across 11 benchmarks — coupled with clinically meaningful attention patterns — positions OphCLIP as a foundation model for ophthalmic surgical workflow understanding, opening avenues for more specialised and context-aware AI in eye surgery.
Key Contributions
- Constructed OphVL — the first large-scale ophthalmic surgical VLP dataset with 375K clip-text pairs from 7.5K hours of video, 15× larger than existing surgical VLP datasets.
- Proposed hierarchical vision-language pretraining that learns both fine-grained (clip-narration) and long-term (video-title) representations through an alternating training strategy.
- Introduced silent-video retrieval augmentation — a dynamically updated memory bank of 30K+ silent surgical videos that enriches multi-modal learning through cross-video knowledge transfer.
- Achieved state-of-the-art zero-shot performance on 11 benchmark datasets for surgical phase recognition and multi-instrument identification, establishing OphCLIP as a foundation model for ophthalmic surgery.
Authors
Ming Hu, Kun Yuan, Yaling Shen, Feilong Tang, Xiaohao Xu, Lin Zhou, Wei Li, Ying Chen, Zhongxing Xu, Zelin Peng, Siyuan Yan, Vinkle Srivastav, Diping Song, Tianbin Li, Danli Shi, Jin Ye, Nicolas Padoy, Nassir Navab, Junjun He, Zongyuan Ge
ICCV 2025